CADプログラムからエクスポートした3DモデルをWebGLやARサービスにアップロードしようとしたことがある人は、 最大ファイルサイズ、終わりのないプログレスバー、フレームレートの悪さなどの問題に遭遇したことがあるかもしれません。
優れたオンライン・インタラクティブ・エクスペリエンスを作成するには、3D データのサイズとパフォーマンスを最適化することが重要です。また、小さいファイルの方が必要なクラウドストレージが少なくて済み、CDN経由でのデータのプッシュも少なくて済むため、収益にも貢献します。
この記事では、ビジュアライゼーションのために良い3Dモデルを作成するための自動化パイプラインを設計する方法を説明します。これにより、モデルを詳細にオーサリングすることが可能になり、ウェブやARに対応したモデルをいつでも利用したり、最小限の手作業でモデルを作成することができます。
オフラインレンダラで製造やビジュアライゼーションのために3Dモデルをオーサリングした場合、ハンドヘルドデバイスやWebブラウザ、ARアプリケーションなどの低スペックのデバイスでの表示には不向きな場合が多いです。 つまり、コンテンツ制作チームは、スムーズなレンダリングと迅速なダウンロードを実現するために、ソース アセットを最適化したり、低価格のデバイスに変換したりすることに多くの時間を費やしてしまうことになります。
この記事では、3Dアセットの最適化全般、特にこのプロセスがSubstanceマテリアルやライブラリとどのように相互作用するかを見ていきます。
クックアクセスメニュー
3Dモデルを手で最適化することは、退屈で時間がかかるだけでなく、生産パイプラインのボトルネックになるかもしれません。問題は、最適化が本質的にソースアセットの下流にあることで、ソースアセット(3Dモデル、マテリアルなど)に変更があった場合、最適化されたアセットに反映させる必要があることです。そのため、最適化されたコンテンツを早期にプレビューできることと、最適化に費やす時間との間に矛盾が生じます。
制作中にソースモデルが何度か変更されることが予想される場合は、最終的にソースモデルが完成してから最適化した方が効率的です。
そのため、最適化は自動化のよいターゲットになります。芸術的な表現が必要な場所ではありません。
3D 最適化パイプラインの概要
eコマースのような設定を見てみましょう。

3Dモデルのソースは、CADパッケージやDCCパッケージなど様々な場所から入手することができます。頂点とポリゴンに加えて、テクスチャUVと法線情報を持っていると仮定します。
マテリアルライブラリは、3Dモデルで使用するソースマテリアルのセットです。下の画像はSubstance Sourceのもので、マテリアルの出発点としては最適ですが、このようなマテリアルは、実際のマテリアルサンプルから作成したものなど、社内で作成することも可能です。

サブスタンスマテリアルはプロシージャルなので、ユーザーがパラメータを設定したり、プリセットを定義したりすることができます。マテリアルは、特定のアプリケーションの設定と一緒に、マテリアルインスタンスと呼ばれます。例えば、赤と青のレザーマテリアルの両方に同じレザーマテリアルをインスタンス化することができます。

マテリアルを選択したら、それをオブジェクトの特定の部分に割り当てます。カウチの場合、クッションには布素材を、脚には金属素材を割り当てることができます。

同じモデルでも複数の割り当て構成を持つことができます。この例では、同じカウチでもクッションの生地や革が異なる場合があります。

出力対象
デバイスによって機能は異なりますし、前世代の携帯電話とハイエンドPCでは、ブラウザでうまく動作するものが大きく異なる可能性があります。
最もシンプルな形では、パイプラインは次のようになります。
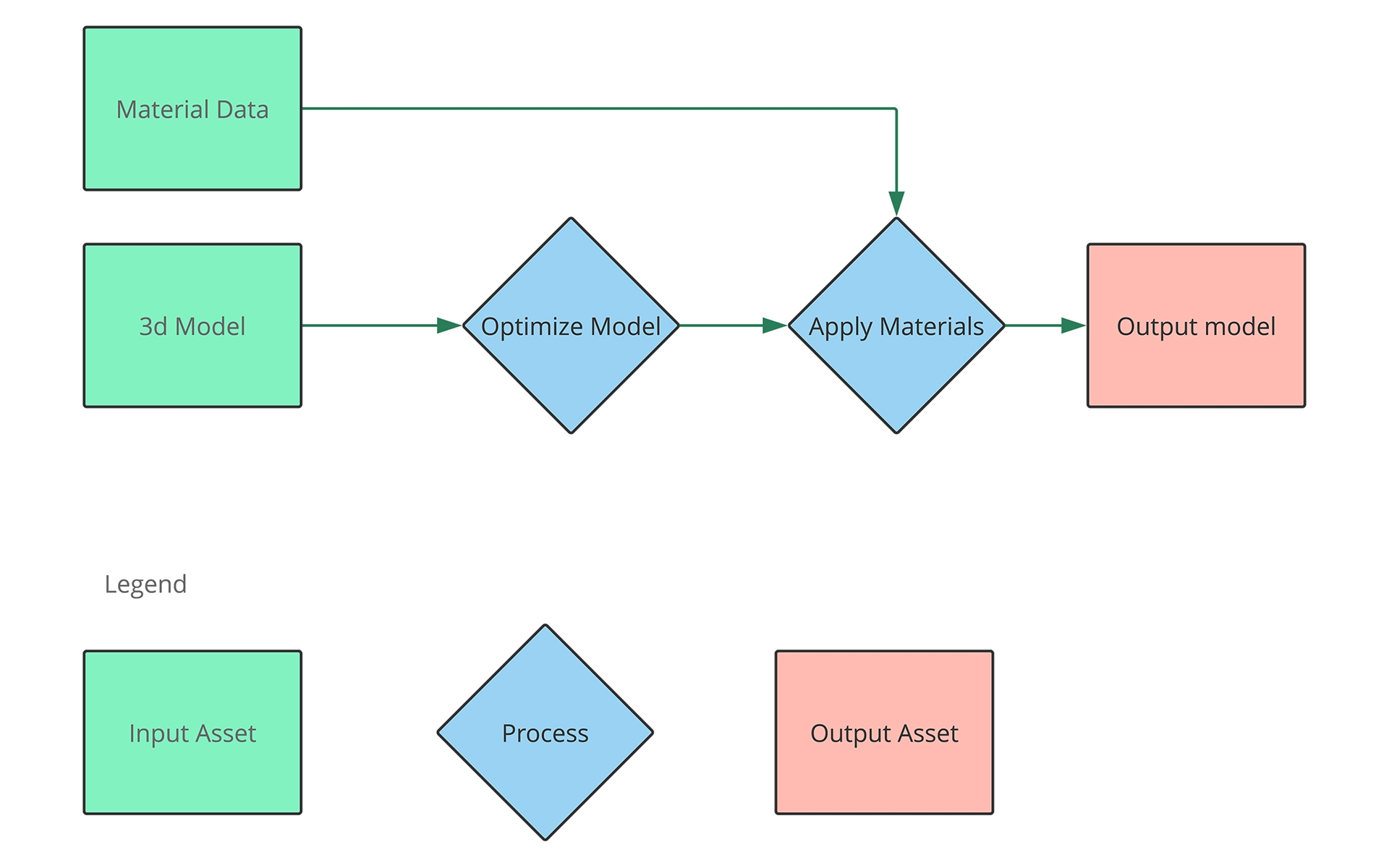
このプロセスでは、1つのモデルが処理されていることが示されていますが、複数の出力に対して複数のマテリアル構成を持つ複数のオブジェクトがこのプロセスを通過するという考え方に注意してください。
概念パイプラインには、モデルの最適化とマテリアルの適用という2つの段階があります。 モデルの最適化はこれらのステップの最初であり、マテリアルの適用はダウンストリームで行われることに注意してください。 つまり、3Dモデルを変更すると、マテリアルの最適化と再適用の両方がトリガーされますが、マテリアルの変更は、再最適化せずに実行できます。
このパイプラインは簡略化されており、実際のパイプラインでは、より多くのステージや依存関係が存在する可能性があります。
効率よく自動化するために押さえておくべきこと
上記のような構造化されたパイプラインを使用することで、最適化されたモデルを作成するプロセスを自動化することができます。
アセット・パイプラインを効率的に実行するためには、操作間の関係や、どのデータがどの出力に影響を与えるかを理解する必要があります。これは、ソースデータが変更されたときに何を構築する必要があるのかを迅速に把握できることを意味します。
いくつかの例を紹介します。
- マテリアルライブラリ内のマテリアルを変更した場合、そのマテリアルを使用した出力はすべて再構築する必要があります。
- 新しい出力ターゲットが追加された場合、すべてのモデルをそのターゲットに対して処理する必要があります。
- 3Dモデルが変更された場合、そのモデルのすべてのターゲットのすべての構成を再構築する必要があります。
自動化プロセスをいつ、どのようにトリガーするかは、どれだけ高速な結果が必要かと、どれだけの計算能力を使用するかのバランスです。何かが変更されるたびに実行をトリガーすると、高速な結果が得られますが、すぐに変更されるモデルの処理に多くの時間を費やすことになるかもしれません。
もう1つのアプローチは、処理能力がより利用可能またはより安価なときに毎晩プロセスを実行することです。つまり、最新のモデルを毎朝準備する必要があります。
また、ユーザーが必要なときに最新のモデルを手に入れることができるように、モデルの処理を実行するタイミングをユーザーに決めさせておくことも可能です。
3Dワークフローの一部を自動化することでよくある懸念は、芸術的なコントロールを失うことです。なぜなら、すべての芸術的な決定は自動化が行われる前に行われるからです。 最適化の段階は、.tiffファイルとして保存されている画像を.jpeg形式に圧縮してからウェブサイトに掲載するのと同じように考えてください。 最適化ステージを自動化することで、配信用モデルの最適化に時間を費やす必要がないため、クリエイティブな作業に時間を割くことができるはずです。
自動化されたソリューションで考慮しなければならない主なことは、手動による修正がいつどのように起こるかということです。 プロセスの出力が特定のモデルで十分でない場合、本能的には生成された出力アセットを修正することが多くなります。このアプローチの問題点は、アセットが変更されるたびに修正を再適用する必要があることです(変更はオートメーションパイプラインの下流にあるため)。一般に、出力のすべての調整は、自動化パイプラインの設定として実行する必要があります。これにより、次にパイプラインが実行されるときに出力を適用できます。モデルが最終的な状態であることを確信していない限り、手動での修正はお勧めしません。
微調整に適したアプローチは、階層的な設定の上書きです。パイプラインのデフォルト値はアセットごとに上書きできるので、うまくいかないアセットに対して、他のアセットに影響を与えることなく、より高い品質の値を設定することができます。
なぜ最適化するのか?
入力データの最適化は、ウェブやハンドヘルドデバイス用の優れた3Dモデルを作成するための鍵となります。 CADモデルまたはハイエンドレンダリング用に作成されたモデルは、細かすぎたり、大きすぎたりするので、一般的には目的には適していません。
最適化で改善したいことは主に
- レンダリングパフォーマンス
- バッテリーの寿命
- ダウンロードサイズ
- メモリ使用率
これらの異なる目標は概ね一致しています。小さいモデルの方が一般的にレンダリング速度が速く、デバイスのバッテリー消費量も少なくて済みます。
最適化されたモデルの評価
何のために最適化するのかを掘り下げる前に、結果の視覚的な品質をどのように評価するのかを確認することが重要です。そのモデルがどのような意味で使われているのかを踏まえて、常に評価することが鍵となります。 400×400ピクセルサイズのウェブビューアやハンドヘルドデバイスで見栄えの良いモデルを作成する場合、詳細を保存したり、近くでズームしないと見えないアーチファクトを除去するために設定を微調整することに時間を費やすことは、詳細すぎてダウンロードするには重すぎるモデルを出荷することを意味します。
レンダリングパフォーマンスに関しては、ベンチマークを行わずに何が最も効果的なのかを予測することは必ずしも容易ではありません。しかし、以下に概説されているように、多くの発見を助ける方法があり、それらを組み合わせることで良い結果が得られる傾向があります。 また、目標のフレームレートとダウンロードサイズに達した場合でも、GPUの使用率が低いほどバッテリーの消費量が少ないため、ハンドヘルドデバイスでは小型化と高速化が重要です。ゲームアーティストのためのGPUパフォーマンスの記事では、このトピックをより詳細にカバーしており、レンダリングが速い3Dモデルの構成要素について学ぶのに良いリソースとなっています。
ポリゴン数
ポリゴン数とポリゴン密度は、モデルのレンダリングを高速化し、ダウンロードを高速化する上で重要な部分です。ポリゴン数と頂点数が増えると、イメージを生成するためにGPUがより多くの計算をしなければならなくなります。
GPUは一般的に、より大きく、より均一なサイズのポリゴンをレンダリングするのに適しています。 GPUは高度に並列化されており、より大きなポリゴン用に最適化されています。 ポリゴンが小さくて薄いほど、マスクされた領域でこの並列処理が無駄になります。 この問題は「オーバーシェーディング」と呼ばれ、上記のリンクされた記事で説明されています。
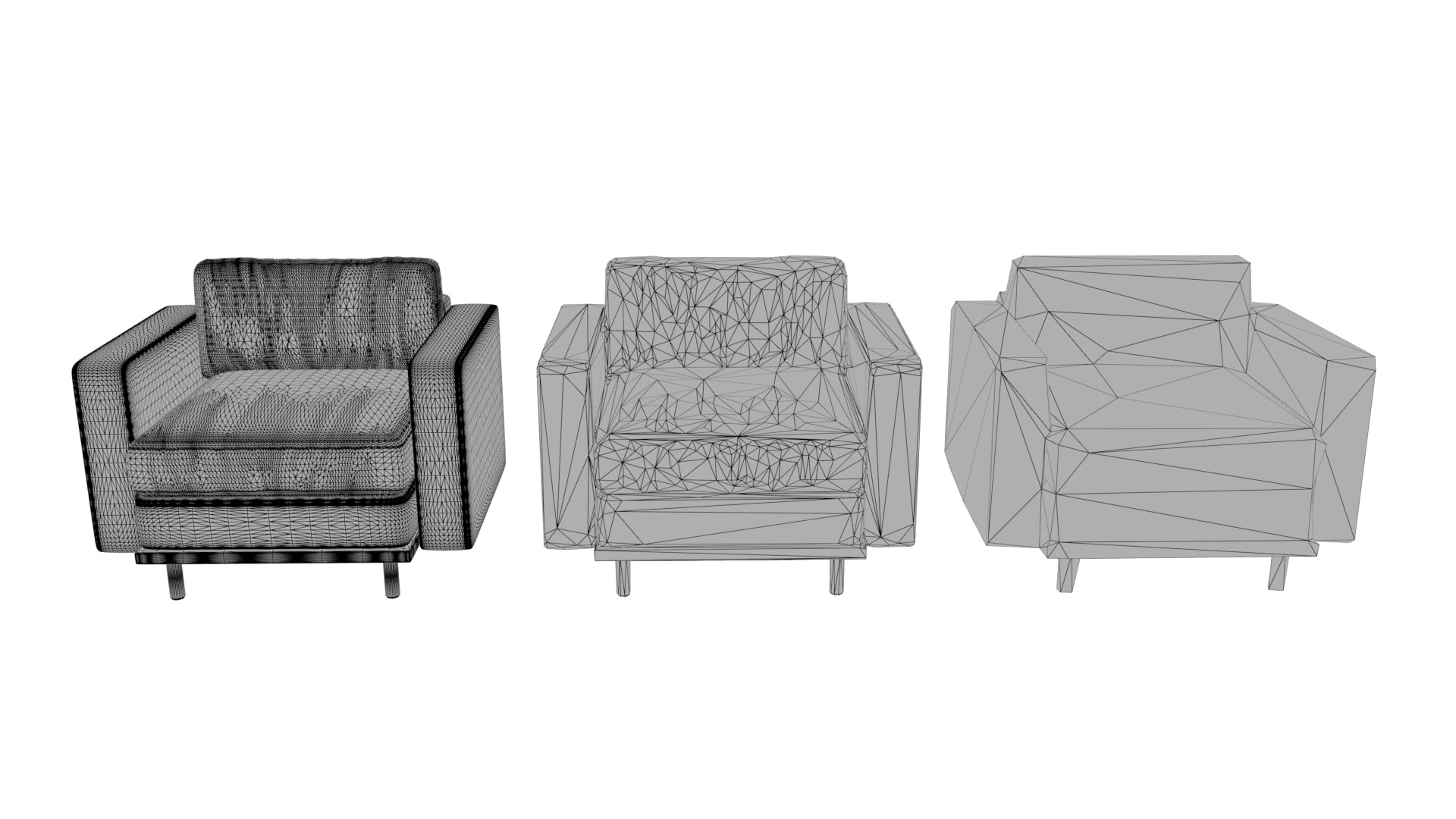
一般的には、制作されたモデルのワイヤーフレームを見て、想定されるサイズで可視化する際に、あまり密度が高くないことを確認しておくと良いでしょう。
詳細を犠牲にすることなくポリゴン数を減らす効果的な方法は、法線マップを使用することです。物体のシルエットよりも、照明が物体とどのように相互作用するかに敏感になっているという考え方です。これは、三角形データの詳細を法線マップに移動して(つまりモデルからテクスチャに移動して)、より大きなポリゴンを使用しても、ライティングで元のデータの詳細を得ることができることを意味しています。
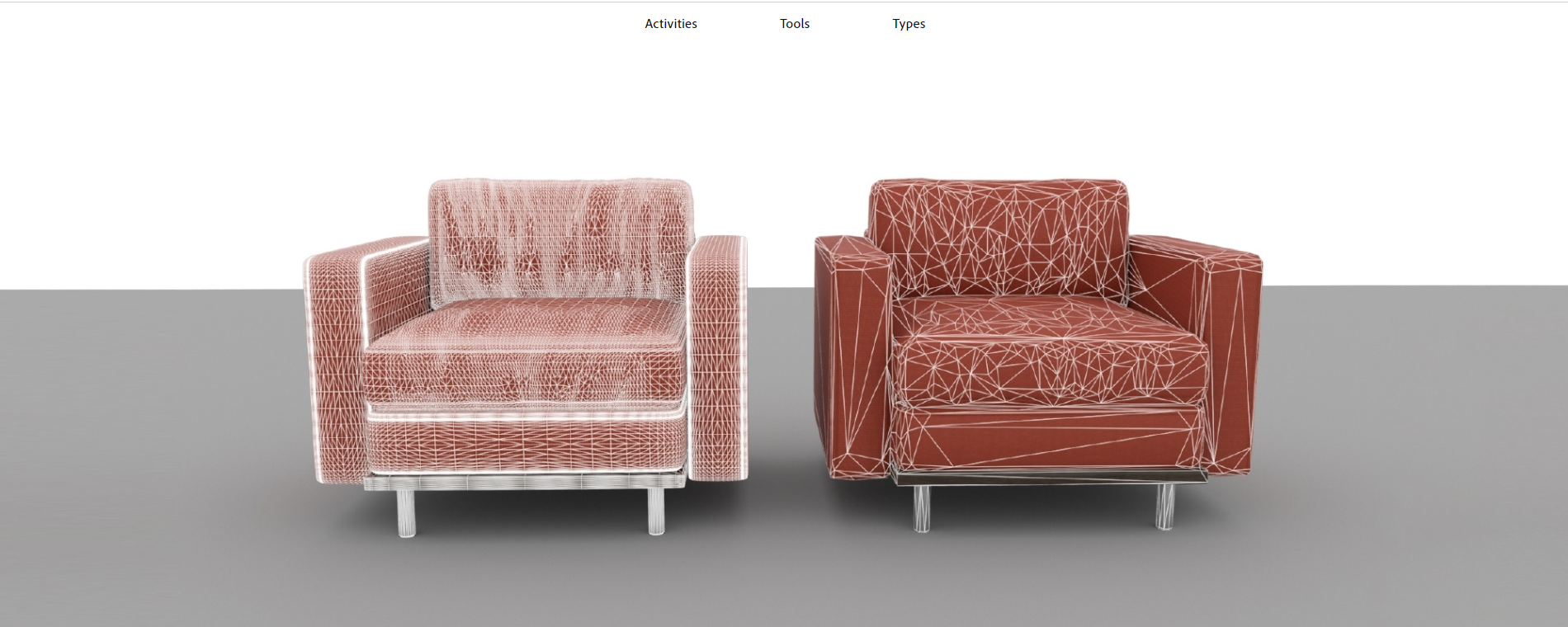
これは、元のモデルの詳細を含む法線マップなし(左)と法線マップあり(右)で最適化された同じモデルです。

細部のほとんどが法線マップにあるレベルにモデルを最適化すると、メッシュのUVマップも向上します。UVマップを作成するとき、細部や鋭いエッジが問題になることがよくあります。単純なモデルでは、大きなグラフが少なくなり、パディングで無駄になるスペースが少なくなり、目に見える継ぎ目が少なくなる傾向にありますが、これは自動的にUVマップ化されたモデルの問題となります。
GPUドローコール
ドローコールは、オブジェクトをレンダリングするためにレンダラーが GPU と通信する必要がある回数を表します。 一般的には、あるオブジェクトから別のオブジェクトに切り替えたり、別のテクスチャを使いたいときにGPUに通知する必要があります。つまり、複数のパーツにセグメント化されているオブジェクトや、多くの異なるマテリアルを使用しているオブジェクトは、単一のテクスチャセットを持つ1つのメッシュのみで構成されている同じモデルよりもレンダリングにコストがかかります。
テクスチャ解像度
GPUは、モデルが表示されるサイズに適した解像度のテクスチャを選択するのに優れており、高すぎるテクスチャ解像度の使用に関連するパフォーマンスと品質の問題を回避します。 出荷するモデルの表示制約を考えると、不必要に高解像度のテクスチャを含めるのは簡単です。これらのテクスチャは実際には完全な解像度では表示されないため、ユーザーにとって不必要なダウンロード時間が発生します。
オーバードロー
オーバードローは、他のポリゴンの背後にあるポリゴンをレンダリングするときに発生するものです。 ほとんどのオブジェクトでは、ある程度のオーバードローは避けられません。ただし、単純な表示シナリオの場合、ユーザーがモデルをどのように操作しても表示されないポリゴンが存在する可能性もあります。例えば、ソファのフレームの上にシートクッションを個々のオブジェクトとして敷き詰めてモデル化したソファを想像してみてください。ユーザーがクッションを取り外せないシナリオでは、クッションの下部と、クッションが配置されているフレームの部分が表示されることはありません。

優れた最適化ソリューションは、これらの不要な領域を特定して取り除くことができるので、見えない領域のポリゴンをダウンロードしたりレンダリングしたりする必要がありません。 さらに重要なことは、多くのテクスチャリングシナリオでは、テクスチャイメージスペースがこれらの見えないポリゴンに割り当てられていることです。つまり、テクスチャデータが無駄になり、ダウンロードサイズに悪影響を及ぼし、実際に表示される領域のテクスチャ解像度が低下します。
知的財産を守るための最適化の役割
最後に、CADプログラムからのデータを操作する場合、3Dモデルには、製品の製造方法に関連する詳細が含まれていることがよくあります。 最適化ソリューションは、内部オブジェクトを削除し、細部を法線マップおよびテクスチャ情報に変換できます。 これにより、視覚化のみを目的としたモデルから製品をリバースエンジニアリングすることが困難になります。
優れたパイプラインの基礎
上で述べたことのすべての側面を組み込んだ自動パイプラインを実装することは、挑戦的な作業になるかもしれません。しかし、基本を正しく理解することで、後で多くの頭痛の種を救うことができます。
データの配置
自動化を成功させるための前提条件は、データに対して構造化されたアプローチを持つことです。使用されるマテリアルライブラリについての明確な概念を持ち、どのマテリアルがどのオブジェクトに割り当てられているかを明確にすることが非常に重要です。また、このマテリアルをパイプラインから見えるようにして、パイプラインが変更を追跡できるようにし、変更されていないものを再処理する時間を無駄にしないようにします。
すべてのデータは中央のリポジトリに保存し、このリポジトリ外のデータは参照できないようにして、追加の共有ネットワークドライブ(または他のデータが存在する可能性のある場所)をマウントしなくても、ソースアセット全体を見つけることができるようにします。データ形式を選択するときは、自己完結型であるか、他のファイルへの参照に簡単にアクセスできるようにして、追跡に役立てる必要があります。
依存関係の追跡
アセット間の関係を追跡することで、変更されたものだけを再構築することができます。依存関係の追跡とジョブの実行をより細かくすればするほど、増分アセットのビルドは小さくなります。
例として、依存関係の追跡でマテリアルライブラリが単一の不透明なエンティティとして表示されると想像してください。 1つのマテリアルを変更した場合、すべてのモデルを強制的に再構築し、すべてのマテリアルデータが最新であることを保証します。 個々のマテリアルの変更を追跡する代わりに、変更されたマテリアルを使用しているオブジェクトのみを再構築することができます。
実行
依存関係が解決されると、目的の出力を生成するためにいくつかのビルドタスクが必要になります。これらのタスクは多くの場合、ほとんど独立しており、並行して実行できます。これは、ビルドプロセスを複数のCPUまたはマシンに拡張できることを意味します。実行部分では、これらのタスクをスケジューリングし、適切なツールが呼び出されて必要な出力が得られるようにします。
最適化パイプラインで実行されるタスクの例としては、以下のようなものがあります。
- メッシュの最適化
- テクスチャレンダリング
- テクスチャ圧縮
- シーンアセンブリ
キャッシュ
ビルドプロセスの中間結果をキャッシュして、増分ビルドを高速化できます。例としては、最適化の低ポリゴン出力が挙げられます。これは、デプロイの準備が整う前にテクスチャを適用する必要があるため、アセットとしては直接使用できないかもしれません。ただし、この低ポリゴンアセットは、中間ステップとしてキャッシュできます。こうすることで、アセットで使用しているマテリアルを更新した際に再構築する必要がなく、処理をショートカットして最適化をやり直さずに済むようになります。キャッシュは、再作成できないデータを失うことなくクリーンアップできるので、これを解決する便利な方法です。キャッシュにより、サイズを常に剪定して、インクリメンタルビルドのパフォーマンスと一時的なデータ保存のバランスを取ることができます。
サンプルパイプライン
このやや抽象的な記事に何か具体的なものを提供するために、私はアセット最適化パイプラインのシンプルな実装を構築することにしました。
ここでの私の意図は、パイプラインのさまざまな側面を示すことです。特に、アセット最適化のワークフローにおいて、Substanceマテリアルがどのように関与できるかを紹介したいと思います。
このパイプラインの目的は、高解像度の3D家具モデルを取得し、小さくて高速なレンダリングが可能なモデルを自動的に生成することです。このパイプラインは主にPythonで実装されており、1台のWindowsマシン上でローカルに実行することを目的としています。
元々のパイプラインはこんな感じでした。
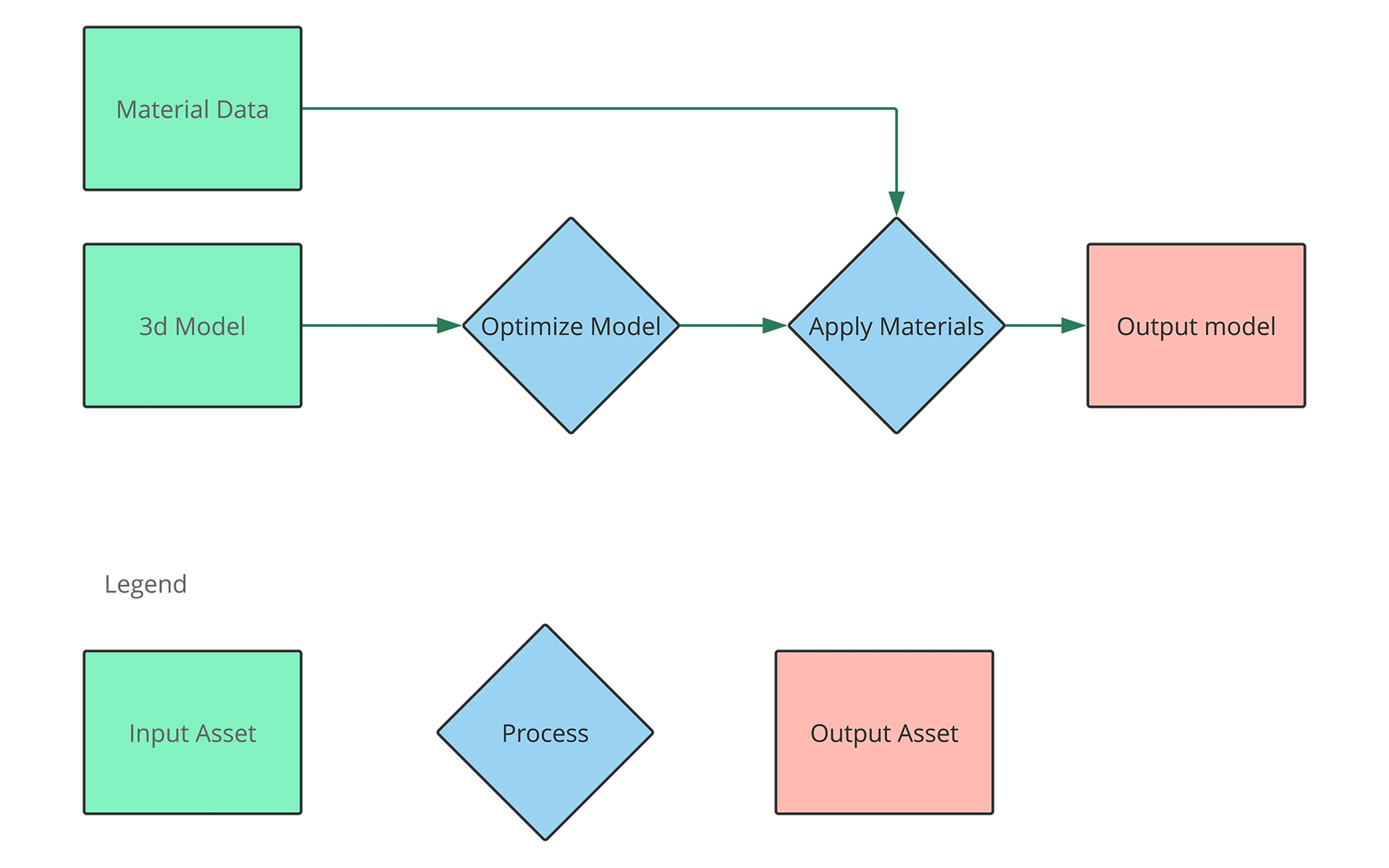
処理ボックスに詳細を追加すると、このようになります。

これは、サンプルパイプラインを通過する単一の最適化されたモデルの概要です。 このパイプラインは、同じモデルの複数のモデルと複数の品質に適用できます。 派生アセットは、増分ビルドを高速化するためにビルドシステムによってキャッシュできる中間出力を表します。
データ
このパイプラインのデータは、物事を可能な限り単純にするためのディスク上のファイルのセットです。 それらは次のように分けられます。
- メッシュ:.objファイル
- ソースマテリアル:Substance.sbsarファイル
- マテリアルライブラリ:プリセット、パラメータ、マテリアルスケーリングを選択するための追加設定を含む.sbsarファイルを参照する.jsonドキュメント。
- マテリアルの割り当て:.jsonは、モデルのパーツをマテリアルインスタンスおよびモデルごとのスケーリングに関連付けるドキュメントです。
- パイプライン:モバイル、VRなどの最適化ターゲットプロファイルを説明する.jsonドキュメント。
- ジョブ:最適化するモデル、使用するマテリアルの順列、出力を生成するパイプラインを説明する.jsonドキュメント。
メッシュファイル形式としてのOBJ
ジオメトリに.objファイルを使用する理由は、そのシンプルさにあります。簡単に作成して共有することができます。テキストベースなので、グループ名が抜けていたり、何らかの理由で間違っていたりしても簡単に編集できます。
パイプラインのメッシュに対する主な制約は、UVチャートがUVページ内に収まる必要があるということです。シェイプの上にマテリアルをタイル状に配置することはできませんが、必要であれば、重ねて配置したり、別のページに配置したりすることはできます。 理想的には、すべてのUVチャートは、モデルのワールドスペースでのサイズに相対的なサイズである必要があります。これにより、テクスチャはすべてのパーツに同じスケールで適用されます。
下の図では、同じモデルの2つの異なるUVレイアウトを見ることができます。左側のレイアウトでは、UVタイルの境界を横切るチャートがあるため問題が発生します。

マテリアルライブラリ
マテリアルライブラリのフォーマットは、.obj MTLフォーマットではなく、カスタムの.jsonファイルを使用しています。MTLフォーマットはSubstanceマテリアルのバインディングやプロシージャルパラメータの設定に対応していないので、これらの機能を備えたシンプルなカスタムフォーマットを導入することにしました。
これは、マテリアルライブラリのマテリアルインスタンスの例です。
{
// ...
// Leather is the name of the instance
"Leather": {
// sbsar file referenced
"sbsar": "${assets}/material_library/sbsar/Sofa_Leather.sbsar",
"parameters": {
// These are parameters on the sbsar
"normal_format": 1,
"Albedo_Color": [
0.160,
0.160,
0.160,
1
],
"Roughness_Base": 0.353
},
"scale": [
// A material relative scale for the UV
20.0,
20.0
]
}
// Additional material instances
// ...
}
サンプル パイプラインでは、すべてのマテリアル インスタンスが単一のマテリアル ライブラリ ファイルに格納されます。
マテリアルは、以下のマップを使用してPBRメタリックラフネスをベースにしています。
- Base color
- Normal
- Roughness
- Metallic
マテリアルの割り当て
マテリアルの割り当ては、モデル内のパーツを特定のマテリアルインスタンスに関連付ける個別のファイルです。 マテリアルの割り当てには、特定のモデルのスケール係数も含まれており、異なるモデル間のテクスチャチャートのスケール間の違いを補正できます。
マテリアルの割り当てをジオメトリから分離することで、同じモデルに対して異なるマテリアル構成を指定したり、同じグループ名を共有するモデル間でマテリアル構成を共有したりすることができます。
マテリアルの割り当て構成の一例です。
{
// Legs is the name of the part in OBJ file
// If similar scenes share part names the same
// material assignment file can be used for all of them
"Legs": {
// Material refers to a material instance
// in the library
"material": "Metal",
// Scale is the scale of the material associated with this
// part. It will be multiplied by the scale from the
// material instance
"scale": [
1.0,
1.0
]
},
// Additional assignments to other parts
"Cushions": {
"material": "Leather",
"scale": [
1.0,
1.0
]
},
"Frame": {
"material": "Wood",
"scale": [
1.0,
1.0
]
}
}
出力形式としてのGLB
.glbファイルは、メッシュデータ、シーンデータ、テクスチャを1つのファイルにまとめた.gltfのバージョンです。私がこのプロセスの出力フォーマットとして.glbを使用しているのは、メッシュ、マテリアル、および生成されたすべてのテクスチャをコンパクトに表現したファイルであり、ウェブおよびモバイル3Dビューアのための業界の幅広いサポートを備えているからです。
パイプライン
パイプラインは、特定のターゲットハードウェアに対して実行される最適化のさまざまな側面を記述しています。
パイプラインの例は以下のようになります。
{
"import": {
// Resolution for reference source textures
// Insufficient resolution in the source textures
// will come out as blurry areas in the model
// Must be an integer power of 2
"material_resolution": 2048
},
"reference": {
// Enable or disable reference model
// creation
"enable": true
},
"optimize": {
// Target size in pixels for which the model
// quality should be optimized. Anything above
// 2000 will be very time consuming to produce
"screen_size": 600,
// Resolution for the utility maps for the model
"texture_resolution": 1024,
// Bake tangent space using Substance Automation
// Toolkit if true, use Simplygon if false
"bake_tangent_space_SAT": true,
"remeshing_settings": {
// Angle in degrees between surfaces in
// a vertex to split it with discrete
// normals
"hard_edge_angle": 75
},
"parameterizer_settings": {
// How much stretching is allowed inside
// a chart in the generated UV layout for
// the model
"max_stretch": 0.33,
// How prioritized large charts are for the
// UV layout
"large_charts_importance": 0.2
}
},
"render": {
// Texture resolution for the atlas
// for the optimized model. Should typically
// be the same as the texture_resolution in
// optimize
"texture_resolution": 1024,
// Offset for mip map selection. 0 is default,
// Negative values gives sharper and noisier results
// Positive values give blurrier results
"mip_bias": 0,
// Enable FXAA post processing on the map to give
// smoother edges between different materials
// (doesn't apply to normal maps)
"enable_fxaa": true,
// Blurring of the material id mask before compositing
// to give smoother borders between materials
// (doesn't apply to the normal map)
"mask_blur": 0.25,
// Enable FXAA post processing on the normal map to
// give smoother edges between different materials
"enable_fxaa_normal": true,
// Blurring of the material id mask before compositing
// the normal map to give smoother borders between
// materials
"mask_blur_normal": 0.25,
// Clean up edges around charts on normal maps
"edge_clean_normal_maps": false,
// Normal map output format and filtering
// For most cases 8 bpp is enough but
// for low roughness and 16bpp is needed to avoid
// artifacts
"output_normal_map_bpp": 8,
// Enable dithering for the normal map. Typically only
// relevant for 8 bpp maps
"enable_normal_map_dithering": true,
// Dithering intensity. Represents 1/x. Use 256 to
// get one bit of noise for an 8bpp map
"normal_map_dithering_range": 256,
// Paths to tools for compositing materials and
// transforming normal maps
"tools": {
"transfer_texture": "${tools}/MultiMapBlend.sbsar",
"transform_normals": "${tools}/transform_tangents.sbsar"
}
}
}
ジョブ
ジョブは、すべてのモデル、マテリアルの組み合わせ、パイプラインが指定されたプロセスのエントリーポイントです。これはジョブの例です。
{
// Scenes to optimize
"scenes": {
"sofa-a1": {
// OBJ file with geometry in
"mesh": "${assets}/meshes/sofa-a1.obj",
// Different material variations to produce for this model
"material_variations": {
// These are references to material assignment files
"sofa-a1-leather": "${assets}/material_bindings/leather.json",
"sofa-a1-fabric": "${assets}/material_bindings/fabric.json"
}
},
// Additional scenes goes here
// ...
},
// The material library with material instances in to use
"material_library": "${assets}/material_library/material_library.json",
"pipelines": {
// A pipeline to run for the scenes
"lq": {
// Reference to the definition file
"definition": "${assets}/pipelines/lq.json",
// Paths for reference models and optimized models for
// this pipeline
"output_reference": "${outputs}/lq/reference",
"output_optimized": "${outputs}/lq/optimized"
},
// Additional pipelines to run
// ...
}
}
パイプラインのコア言語としてのPython
パイプラインの実装にはPythonが使用されます。 これは幅広いサポートを備えた言語であり、私たちがすぐに取り組む多くの問題に対応する機能が付属しています。 プロセスで使用したいいくつかのツールのバインディングがあり、他のアプリケーションへのブリッジを作成するのではなく、パイプラインの構築に集中することが簡単になります。
SCons の依存関係の追跡と実行
パイプラインに使用される依存関係の追跡および実行システムは、SConsビルドシステムです。 これはPythonベースのビルドシステムであり、依存関係を追跡し、前回のビルド以降に変更されたデータのみを再構築することで、増分ビルドのコストを最小限に抑えようとします。 これは、エグゼキュータとして機能し、中間結果のキャッシュも実行することを意味します。
Pythonベースのビルドシステムを使用すると、ビルド操作とのやり取りが簡単になるため便利です。 pipモジュールシステムでも利用できるため、Python環境を持っている人なら誰でも簡単にインストールできます。
パイプラインはPythonスクリプトとして直接実行することにも対応しており、デバッグがしやすくなっています。スクリプトから直接パイプラインを実行する場合、実行するたびにゼロから再構築され、独立したタスクの並列処理は行われません。
最適化
最適化のために、SimplygonのRemesher2.0を使用しています。 Simplygonは、ゲーム業界におけるポリゴン最適化のゴールドスタンダードと見なされており、多くの制御を備えた非常にコンパクトなメッシュを作成できます。 さまざまなシナリオに適用できるいくつかの異なる最適化戦略がありますが、物事を単純にするために、パイプライン用に1つを選択しました。
Remesherは、最適化されたメッシュに対して多くの望ましい特性を持っています。
1. 積極的にモデルを最適化し、正しく使用すれば、より少ないポリゴンでも桁違いに良い結果が得られることがよくあります。
2.モデルのすべての内部ジオメトリをクリアして、オーバードロー、見えないサーフェスへのテクスチャの割り当てを減らし、モデルから無関係な情報や独自の情報を削除します。
3.モデル全体の新しいテクスチャアトラスを作成します。つまり、モデルの最初の設定方法に関係なく、同じ量のテクスチャデータを使用して単一のドローコールとしてレンダリングできます。
4. ソースメッシュからデスティネーションメッシュへのマッピングを生成し、ソースメッシュ上のテクスチャや法線などを最適化されたモデルに高品質で正しく転送できるようにします。
5. 特定の表示サイズに最適化することができます。特定のサイズや解像度のビューアで予測可能な品質でモデルを表示したい場合、この情報をターゲット解像度として入力することができます。このパイプラインではこの機能は使用されていませんが、Remesherはこの特定の品質のためのテクスチャサイズを提案することもできます。
6.過去に私はSimplygonで働いていました。 したがって、この場合にRemesher 2.0を使用する私自身の理由の1つは、それが生成する結果のタイプと、それを適切に使用するようにツールを構成する方法に精通しているからです。
Simplygonはまた、このパイプラインに適した以下の機能を持っています。
1.すべての最適化とシーン作成を駆動できるPythonAPIがあり、このツールを、同じくPythonで作成されるパイプラインの残りの部分と簡単に統合できます。
2..objファイルと.glbファイルの読み取りと書き込みが可能です。 これにより、マテリアルとテクスチャの管理方法に関する多くの制御が可能になります。 したがって、このツールを使用して、カスタムマテリアルを使用してソースデータを読み取り、Substanceを使用して生成されたテクスチャを使用して.glbファイルを書き出すことができます。
Remesherは積極的な最適化手法であり、遠くから見たモデルに最適です。ただし、オブジェクトのシルエットとメッシュトポロジに非常に大きな影響を与える可能性があるため、綿密に検査する必要があるモデルには適していません。そのため、すべてのビジュアライゼーションのシナリオに適したソリューションではないかもしれません。具体的には、ここで使用されている実装では透過性が適切に処理されないため、このパイプラインでは回避する必要があります。オブジェクトのメッシュトポロジーを壊すことで、アニメーションなどのために分離しているはずの部分が結合してしまうことがあるので、そのような場合には特に注意が必要です。
3D最適化のためのソリューションは他にもたくさんありますが、Simplygonはその膨大な数の機能と私のこれまでの経験から、私にとって自然な選択でした。
最適化されたモデルをテクスチャリングするためのSubstance
ソースメッシュから最適化されたメッシュにテクスチャを適用するためにSubstance Automation Toolkitを使用しています。
Substance Automation Toolkitを使用すると、Substance Designerを使用してテクスチャ転送プロセスで使用されるすべての操作を構築し、パイプラインのPythonスクリプトからそれらを呼び出すことができます。 また、最適化とテクスチャ生成を2つの個別の段階として分離できます。つまり、SConsは中間ファイルを個別に追跡できます。 このように、モデルが変更されていない限り、最適化自体はマテリアルから独立しているため、マテリアルデータを変更しても、ジオメトリの最適化はトリガーされません。
パイプライン
パイプラインは以下の段階から構成されています。
テクスチャレンダリング
このステージでは、処理されたすべてのモデルのマテリアルバインディングを確認し、使用されたすべてのマテリアルのSubstance PBRイメージをレンダリングします。

リファレンスモデルの作成
リファレンス ステージでは、オリジナル モデルとレンダリングされたテクスチャを組み合わせて、リファレンス .glb ファイルを作成します。
このリファレンス用.glbファイルは下流では使用されませんが、「前」と「後」のショットを取得するために持っていると便利なアセットです。また、出力の問題が最適化中に発生したのか、それともソースデータにあるのかという点で、デバッグにも役立ちます。
上記の.objセクションで説明されている入力UV座標の制限により、UVチャートはマテリアルスケールと割り当てスケールに基づいてスケーリングされます。 これにより、テクスチャは最適化されたモデルと同じスケールになります。
最適化
最適化ステージでは、ソースモデルをロードし、Simplygonを使用して再メッシュ化処理を実行します。モデルは、このプロセスの一部として、元のものとは関係のない新しいUVセットを取得します。
再メッシュ化を行うことに加えて、Simplygon Geometry Castersを使用して、ソースモデルから最適化モデルにテクスチャデータを転送するためのテクスチャのセットを生成します。これらのマップはすべて、最適化されたモデルの新しいUV空間で表現されます。
1.マテリアル ID。このマップは、テクセルごとのマテリアルのインデックスをエンコードします。このマップを使用すると、どのマテリアルがソースモデルのどのポイントに割り当てられているかを判断することができます。

2.UV。 このマップは、最適化されたモデルのテクスチャ空間でソースモデルのUV座標をエンコードします。 このマップを使用して、最適化されたモデルにデータを転送するために、ソースモデルのテクスチャのどこを調べるかを決定できます。
このマップは0-1の間の16bppのマップなので、マテリアルのタイリングにUVが使えないことに注意してください。割り当てからのマテリアルのタイリングは、テクスチャレンダリングの段階で適用されます。
UVリマップテクスチャでは、高ポリゴンモデル上のUV座標を見つけることができるので、元のUVを使用して最適化されたモデルをテクスチャ化することができます。

3. 最適化されたモデルのUV空間で表現されたソースモデルのアンビエントオクルージョン。アンビエントオクルージョンは、ソースモデルの詳細を使用して作成されるため、最適化で失われた可能性のある領域のオクルージョンを提供し、失われたジオメトリの視覚的な手がかりを提供します。
4.最適化されたモデルのUV空間での、ソースモデルのワールド空間の法線と接線。 これらの2つのマップを用いて,元のモデルの失われた法線を捕捉し,さらに処理を進めるために,元のモデルに適用された接線空間法線マップをワールド空間に転送することができます。
5.最適化されたモデルのワールドスペースの法線と接線。 これらのマップを使用して、ソースモデルから最適化されたモデルの接空間法線マップに法線を転送し、ソースメッシュ法線とそれに適用された接空間法線マップの両方をキャプチャできます。
最適化されたモデルのテクスチャレンダリング

このステージは、Substance Automation Toolkitを使用して、ソースモデルからすべてのソースマテリアルマップを転送する多段階のプロセスです。Substanceグラフは処理にジオメトリを関与させることができないため、最適化ステージのマップを使用してマテリアル転送を行います。基本的なプロセスでは、UV転写マップを使用してサンプルする位置を選択し、マテリアルIDマップを基にテクスチャをピックします。
ユーティリティマップとマテリアルマップに加えて、このステージでは、タイリングとフィルタリングを制御するために、マテリアルごとのスケールとミップマッピングに関連するパラメータを入力として使用します。
法線マップの場合、ソーステクスチャスペースの法線マップをサンプリングするだけでなく、ソースメッシュとデスティネーションメッシュの法線と接線を使用して、最適化されたモデルの接線空間の法線マップを作成する必要があるため、プロセスはより複雑になります。
このプロセス全体は、配置後まで遅延する可能性があることに注意してください。 モデルをマテリアル構成シナリオで使用する場合は、サーバー上のSubstanceエンジンまたはSubstance Automation Toolkitを使用してこのプロセスを実行し、ユーザー入力に基づいてオンデマンドで画像を生成できます。 これは、完全な最適化パイプラインを実行するよりも大幅に高速です。
この処理については、「Substance Texture 処理の詳細」のセクションで詳しく説明しています。
最終シーンの組み立て
シーンアセンブリでは、Simplygonを使用して最適化されたジオメトリをロードし、新しいレンダリングされたマップを割り当てて、マテリアルを含む.glbファイルを保存します。
ジョブ処理の実装
ジョブ処理は、ジョブ、パイプライン、マテリアルライブラリなどからのすべての依存関係を理解して追跡するPythonスクリプトとして実装されます。
異なるビルドステージは別々の Python ファイルであり、パイプラインは各ステージに関連するパラメータと入力ファイルを適用します。ファイルとパラメータの内容はキャッシュキーとして機能し、最後の実行からすべて変更されていない場合は、結果を再構築するのではなく、古い結果を再利用することができます。
これは、不必要な再処理を避けるために、各操作に最小限のパラメータセットを適用しようとしていることを意味します。データがどのように剪定されるかの例として、オブジェクトに使用されているマテリアル割り当てファイルで参照されているマテリアルインスタンスのみがパラメーターとして適用され、処理中のモデルによって参照されているマテリアルインスタンスへの変更のみが新しいビルドをトリガーするようにします。
処理スクリプトは2つの方法で実行できます。
- ビルドモード。 このモードでは、すべてのビルド操作を識別し、Pythonから直接実行します。 これはキャッシュを考慮しておらず、パイプラインが実行されるたびにパイプライン全体を再評価することに注意してください。
- 予行モード。 このモードでは、すべての依存関係の解決が実行されますが、パイプラインを実行する代わりに、対応するパラメーターと指定されたすべての入力ファイルと出力ファイルを使用したビルド操作のリストが生成されます。
予行モードの出力は、任意のビルドシステムで消費することができ、その結果を依存関係順に並列にビルドすることができます。
SConsスクリプト
SCons スクリプトは予行モードでパイプラインを実行し、出力を使用してすべてのビルドタスクを指定します。
Pythonスクリプトがビルドモードでタスクを実行するために使用するのと同じビルド操作を使用します。 次に、SConsは、どのタスクが独立しているかを識別し、ビルドが迅速に実行されるように、できるだけ多くのタスクを並行して実行しようとします。 また、どのターゲットがすでに最新であるかを識別し、それらをそのままにして、変更されたターゲットのみが構築されるようにします。
コードパッケージ
パイプラインのコードはSubstance Shareにあります。パッケージにはインストールと実行の手順が含まれています。
結果について
出力モデル
ここでの比較は、最適化されたモデルで作成された参照モデルを比較して行います。
参照モデルではテクスチャ密度が著しく高いため、これは必ずしも同一条件での比較にはなりませんが、モデル間の違いを推定することができます。また、最適化もテクスチャリングプロセスも決定論的なものではないので、あなたの実行と我々の実行では数値が同じではないかもしれないことに注意してください。
サンプルパイプライン
このプロセスには、LQとHQという2つのパイプラインがあり、それぞれ低品質用と高品質用に分かれています。LQは積極的に最適化されており、サムネイルサイズのモデルのラインに沿ったものを意図しています。HQは600×600ピクセルのビューア向けです。
モデルの検査


ポリゴン数
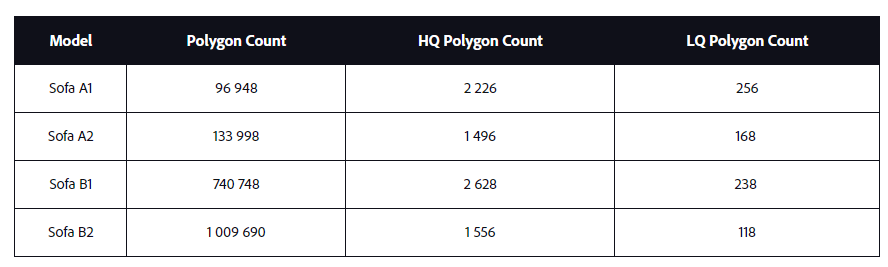
ご覧のように、最適化されたモデルではポリゴン数が桁違いに少なくなっています。また、密度の高いソースモデルの結果として得られるポリゴン数は、密度の低いソースモデルよりも大幅には高くないことにも注意してください。これは、元のポリゴン数に対するパーセンテージではなく、目標とする画面サイズに向けて最適化した機能です。これは、異なるCADパッケージ、ワークフロー、および設計者によって非常に異なるソースデータを生成する可能性があるため、望ましい機能です。
ファイルサイズ
ポリゴンとテクスチャの組み合わせでファイルサイズが決まり、画像が生成されます。
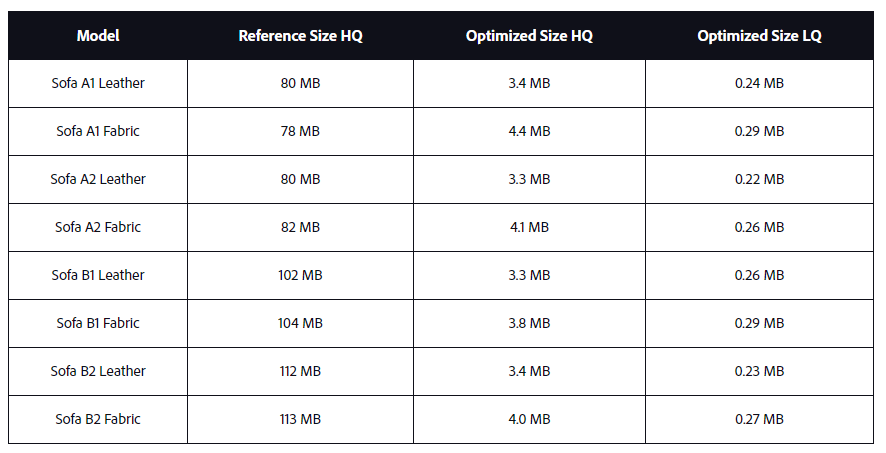
ご覧のように、オリジナルモデルと最適化されたモデルでは、ダウンロードサイズに劇的な違いがあります。 これにはコストがかかり、これらのモデルは本当に綿密に検査することを意図したものではありませんが、より高品質なモデルの追加コストが過剰になるような有意義な視聴シナリオを表しています。公平を期すために、参照モデルはサイズが最適化されておらず、より高い品質レベルが必要な場合は、参照モデルを小さくするためにできることがたくさんあります。
GPUドローコール
最適化されたモデルでは、すべてのマテリアルのテクスチャが1つのアトラスにマージされているため、1回のドローコールでレンダリングすることができます。
ソースモデルは3つの異なるマテリアルグループを使用しました。そのため、ほとんどのレンダラーは、各モデルに対して 3 回のドローコールを送信します。
オーバードロー
最適化されたモデルでは、内部ジオメトリがクリーンアウトされているため、不要なオーバードローがほとんどありません。
Adobe Aeroでモデルをテスト

コンテンツを最適化することで違いが出る実例として、8 つのモデルすべてを使用して Adobe Aero プロジェクトを作成しました。1つのプロジェクトではリファレンスモデルを使用し、1つのプロジェクトでは最適化モデルを使用しました。
プロジェクトはAdobeAeroベータデスクトップで作成され、iPhoneで高速LTE接続で開かれ、モデルをデバイスに同期する時間の違いを比較して、使用できるようにしました。
最初の問題は、Sofa B1とSofa B2の参照モデルを使用してプロジェクトにロードするには重すぎると判断されたため、Aero iPhoneアプリケーションには全く表示されなかったことです。この2つのソースデータはポリゴン数が非常に多く、アプリケーションが正常に動作するように、モデルの重さの上限に達していました。
プロジェクトを開いて同期する時間です。

実行時間
最適化パイプラインは、6コア2.6GHzのIntel Core-7 CPUで実行されました。これにより、2つのマテリアル構成の4つの異なるモデルについて、参照モデルと最適化モデルが生成されます。

ご覧のように、SCons を通して実行した場合、プロセスは約 2 倍の速さになります。これは、6コアを使用できることを考えると少し驚くべきことかもしれませんが、実際には多くのプロセスがマルチスレッド化されています。
SConsの本当の利点は、アセットに最小限の変更を加え、増分ビルドを実行するときに見られます。これは、実行された操作に時間がかからず、ダウンストリームで多くの変更がトリガーされない限り、ターンアラウンドタイムは秒単位でカウントされます。
コンテキストでの実行時間
これらの数値を確認する際に最初に考慮すべき点は、人間が手動でこの作業を実行することと比較することです。 低解像度モデルの作成は、それ自体で時間のかかる作業であり、おそらく数時間の作業が必要になる可能性があります。 これは、ソースモデルが変更されるたびにある程度やり直す必要があるタスクでもあります。 時間消費の観点から、このプロセスを自動化することは大きな勝利です。
もう1つ覚えておくべきことは、このプロセスをユーザーから隠して、別のマシンで実行できることです。 つまり、ビルドマシンのバックグラウンドで実行できるため、このプロセスによってユーザーの速度が低下したり、ワークステーションが不必要に占有されたりすることはありません。
Substance テクスチャ処理の詳細
テクスチャ処理はSubstance Designerで構築されたもので、いくつかのコアコンポーネントが含まれています。
1. UVリマップテクスチャをベースにしたテクスチャからのサンプリング
2. 入力マテリアルIDから画像内のテキストを選択する
3. 法線をある接線空間から別の接線空間に変換する

マテリアルは、マテリアルIDマップを使用して選択されます。 サンプルが描画されるUVは、UVリマップテクスチャから選択されます。 このプロセスでは3Dモデルは必要ないことに注意してください。 これは完全にテクスチャ空間で発生します。 このプロセスはすべてのPBRマップに対して実行され、法線マップは後で追加の接空間変換を受け取ります。
これら3つのことを行うと、ソース・モデルからマテリアルを取り出し、最適化されたモデル上の共有アトラスに転送することになります。
パイプラインでは、上記のポイントの1番目と2番目が1つのプロセスで実装され、PBRマップ((basecolor、roughness、metallic、normal)ごとに個別に実行されます。 ポイント3は、法線マップが最適化されたモデルの接空間と互換性があることを確認するために、法線マップでのみ実行される別個のステージです。
グラフは、この時点で最大22の入力テクスチャに組み込みにされています。 22を超えるマテリアルを含むオブジェクトでプロセスを実行すると、失敗します。
UVサンプリング
ファイル: assets/tools/trilinear_sample.sbsar (すべてのファイルをダウンロード)
この段階では、単一のPBRチャネルのすべてのマップが、UVリマップテクスチャとともに一緒に供給されます。 各テクセルについて、UVリマップテクスチャからのUVを使用して、マップ内のどのポイントをサンプリングするかを選択します。 サンプリングの前に、出力テクスチャでテクスチャタイルが正しく表示されるように、UVはテクスチャIDに指定されたスケールでスケーリングされることに注意してください。
また、UVリマップテクスチャは、アーチファクトを避けるために十分な精度でエンコードするために、1ピクセルあたり16ビットでレンダリングされていることにも注意してください。
ミップマップ
このプロセスで発生する問題は、レンダリングが実行される初期テクスチャが、出力されたレンダリングよりも解像度が高いことです。 これにより、ノイズやモアレなどのエイリアシングアーティファクトが発生する可能性があります。
これを軽減するために、ミップマップを使用します。これは、ソーステクスチャを低解像度に事前フィルタリングし、ソーステクスチャとデスティネーションテクスチャのスケールがほぼ同じであるテクスチャからサンプリングするプロセスです。
サンプリングするスケールを決定するために、UVリマップテクスチャの隣接するピクセルを使用して、特定のテクスチャサンプルでカバーされる領域を推定します。 次に、最も近い2つのテクスチャをブレンドして、ミップマップレベルが一定でない領域でスムーズな遷移を取得します。
また、アーティファクトを回避するために、UVシームの外れ値をカリングします。 このステップの後、出力は大幅に良く見えます。
ミップマップを使用する他の利点は、出力のノイズが少ないことです。 したがって、画像の圧縮率が大幅に向上し、ダウンロードサイズが小さくなります。 従来のミップマップは法線マップに最適なフィルターではないことに注意してください。より良い方法は、失われた法線の詳細がRoughnessマップに移動されるLEANマッピングのようなものを使用することです。 ただし、これはこのパイプラインでは実装されていません。
ミップマップを使用した場合と使用しない場合のテクスチャを比較します。


マテリアルマスキング
ファイル: assets/tools/MultiMapBlend.sbsar (すべてのファイルをダウンロード)
マテリアルチャネルのソーステクスチャが高ポリゴンメッシュのUVセットを介して再マッピングされたら、次のステップは、このマテリアルが割り当てられている領域にのみ適用されるようにマスクすることです。 このプロセスでは、マテリアルIDマップを使用して各マテリアルのマスクを作成し、マスクされていないピクセルのみを保持します。 これらのマスクは、マテリアル間のエッジを柔らかくするために、オプションで軽くぼかしてグローバルに正規化します。 また、出力テクスチャへのFXAAの適用をサポートし、異なるマテリアル間の継ぎ目を見えにくくします。 このプロセスは、対応するマップを使用して入力テクスチャごとに実行され、結果を1つのマップにマージします。
.sbs ファイルでは、MultiMapBlend/MultiMapBlend_Grayscale と呼ばれるグラフがマスキングを行います。MultiMapBlend_uv/MultiMapBlend_uv_Grayscale と呼ばれるグラフは、UV サンプリング段階からのミップマップされた UV リマップも含めて、操作を実装します。MultiMapBlend_uv/MultiMapBlend_uv_Grayscaleは、テクスチャレンダリング段階でのsbsrenderのエントリポイントです。
法線マップの変換
ファイル: assets/tools/transform_tangents.sbsar (すべてのファイルをダウンロード)
法線マップステージでは、主に2つのことを行います。
1.法線を高解像度モデルから最適化されたモデルの接空間に変換します。
2..sbsarマテリアルからモデルに接空間法線を適用します。
この変換は、最適化ステージで生成されたソースモデルとデスティネーションモデルのワールド空間接線と法線マップを使用して実行されます。 接線空間の法線は、高解像度モデルの法線マップと接線マップのマップによって作成された接線フレームを使用して、ワールド空間に変換されます。
次に、この新しい法線は、低解像度モデルの法線マップと接線マップを使用して、低解像度モデルの接空間に変換されます。
このグラフは16bppで動作し、生成された法線マップにアーティファクトが発生しないように十分な精度があることを確認します。 ユーザーは、16bppまたは8bppの法線マップを出力するかどうかを制御できます。 Roughnessが非常に低いサーフェスを持つオブジェクトの場合、バンディングアーティファクトを回避するために16bppの法線マップが必要になる場合があります。 ただし、これによりダウンロードサイズが大幅に増加するため、目に見える問題がない限りお勧めしません。
このプロセスでは、出力にディザリングを適用することもできます。これにより、8bppに移行するときにこれらのアーティファクトが減少します。 これにより、アーティファクトが見にくくなりますが、これらの光沢のある領域に目に見えるノイズが発生します。
8bppの低凹凸、ディザ付き8bpp、そして16bpp法線マップを比較します。



接線空間変換の実装は normal_space_converter.sbs にあります。
今後の活動
サンプルのパイプラインはかなり限定されていますが、パイプラインによってコンテンツの最適化と配置をより効率的に作業できるようになる方法の概要がわかるはずです。ここでは、拡張性と作業性を向上させるために追加できる改善点をいくつか紹介します。
テクスチャ圧縮
モデルのテクスチャは.pngファイルです。 小さいファイルを取得する方法はいくつかあります。
- パイプラインにpngquantを実装します。pngquantツールは不可逆.pngコンプレッサーであり、ビューアに特別な拡張機能を必要とせずに、品質の低下をほとんど伴わずに.pngのサイズを大幅に削減できます。
- 現在、.gltf/.glbの拡張としてGPUハードウェアテクスチャ圧縮の作業が行われています。これを実装することで、ファイルのサイズを小さくし、ロード時間を短縮することができます。
より良い Substance パラメータのサポート
現在のマテリアルインスタンス化フォーマットは制限されており、スカラー、ベクター、ブーリアンなどで動作します。しかし、enumや、より高度なパラメータ型を使おうとすると、動作がおかしくなるかもしれません。
より多くの最適化オプション/ストラテジー
最適化は、最小限のパラメータセットを持つ単一のアルゴリズムのみを公開しています。より多くのオプションやアルゴリズムを導入して、より広い範囲のターゲットタイプを対象とするのには、それなりの理由があるかもしれません。
メッシュの圧縮
.gltfにはdracoのメッシュ圧縮がサポートされています。ここでの処理のために評価されましたが、データのほとんどがテクスチャで構成されているため、ファイルサイズに大きな影響はありませんでした。
メッシュの共有
このパイプラインでは、異なるマテリアルのバリエーションのメッシュは同一です。結果が.glbではなく.gltfファイルとして書き込まれるセットアップでは、異なるファイル間でメッシュデータを共有してディスク上のスペースを少なくすることができます。
分解処理
最適化もテクスチャレンダリングも、複数のプロセスを呼び出して実装されたオペレーションです。これらの操作をより小さな操作に分解すれば、SCONはより多くの並列性を発見し、より細かい依存関係の追跡を可能にすることができるでしょう。
法線マップの縮小
法線マップは、ミップマップを使用してフィルタリングされます。 これは法線マップに適したフィルターではありません。品質を向上させるために、オブジェクトの凹凸を表示するには細かすぎる法線の詳細を移動することができます。 これは、LEANマッピングに関する論文で説明されています。
アセットリファレンス
現在のアセットリファレンス(.sbsarファイル、メッシュなど)はローカルファイルパスです。 この設定は単一のマシンでうまく機能しますが、パイプラインを複数のマシンにスケーリングする場合は、ある種のURIスキームを使用してファイルを参照し、マシン間で構造化された方法でファイルを参照できるようにします。
設定の上書き
実際の最適化パイプラインでは、正しく出力されないアセットや特別な設定が必要なアセットがあります。 テクスチャ解像度、最適化品質など、アセットごとに繰り返し可能な修正を行う便利な方法は、設定の上書きを使用することです。 これにより、ユーザーはパイプラインごと、アセットごとのプロパティの上書きを実行できます。 これらは、パイプラインのデフォルト値を上書きします。
より大きなスケール
大規模なデプロイメントでは、このようなビルドプロセスを複数のマシンに分散させることができます。しかし、これは SCons では不可能であり、別のビルドシステムを使用する必要があります。
この記事が、3Dグラフィックスを使用した自動ワークフローについて考えるための出発点と、レンダリングが高速な3Dモデルを作成する方法に関する役立つ情報を提供してくれることを願っています。
謝辞
この記事の作業中に貴重な助けを提供してくれた次の人々に感謝します。
Luc Chamerlat、パイプラインをデモンストレーションするためのメッシュとマテリアルを作成してくれました。
Justin Patton、マテリアルの製造、さまざまなメッシュでのパイプラインのテスト、およびパイプラインの改善方法に関するフィードバックの提供。
Nicolas Wirrmann、ディザリングや法線変換などの機能のユーティリティSubstanceグラフを提供してくれました。
Simplygonチーム、パイプラインに必要な機能を追加し、問題が発生したときにバグレポートや質問に迅速に対応してくれました。